import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import fetch_openml
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, ConfusionMatrixDisplay
import shap
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True)
df = housing.frame
X = housing.data
y = housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
🏡 Random Forest Regression with Heart Disease Dataset
What is Bagging?
Bagging (Bootstrap Aggregation) is an ensemble learning technique that helps reduce variance by training multiple models on different subsets of the data (with replacement) and combining their outputs. This makes the final model more robust and stable.
What is a Random Forest?
Random Forest is an ensemble of decision trees built using bagging. Each tree is trained on a random subset of the data and a random subset of features. The final prediction is made by majority vote (regression) or average (regression).
Random Forests are powerful, easy to use, and work well on many real-world problems.
🔧 Key Hyperparameters in Random Forest
We’ll explore the effect of the following hyperparameters:
n_estimators: Number of trees in the forest.max_depth: Maximum depth of each tree.min_samples_split: The minimum number of samples required to split an internal node.
Let’s see how each of these affects performance!
n_vals = [1, 2, 3 ,5 ,8, 10, 50, 100]
train_scores = []
test_scores = []
for n in n_vals:
clf = RandomForestRegressor(n_estimators=n, random_state=42)
clf.fit(X_train, y_train)
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot(n_vals, train_scores, marker='o', label='Train Accuracy')
plt.plot(n_vals, test_scores, marker='s', label='Test Accuracy')
plt.xlabel('n_estimators')
plt.ylabel('Accuracy')
plt.title('Effect of n_estimators')
plt.legend()
plt.grid(True)
plt.show()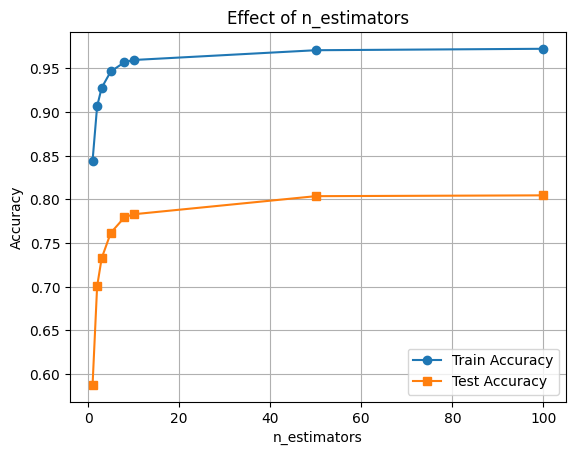
depths = [2, 4, 6, 8, None]
train_scores, test_scores = [], []
for d in depths:
clf = RandomForestRegressor(max_depth=d, random_state=42)
clf.fit(X_train, y_train)
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot([str(d) for d in depths], train_scores, marker='o', label='Train Accuracy')
plt.plot([str(d) for d in depths], test_scores, marker='s', label='Test Accuracy')
plt.xlabel('max_depth')
plt.ylabel('Accuracy')
plt.title('Effect of max_depth')
plt.legend()
plt.grid(True)
plt.show()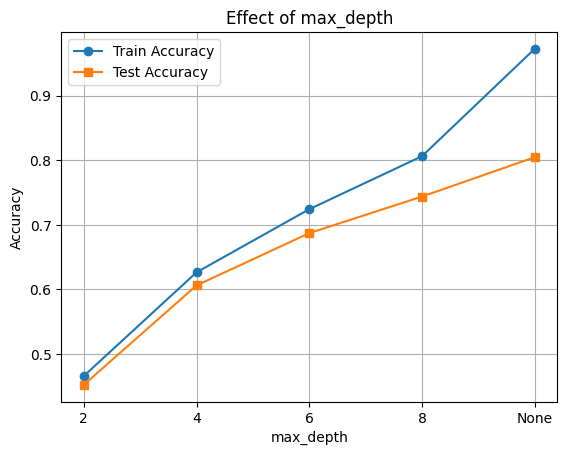
# Evaluate RandomForestRegressor performance with varying min_samples_split
splits = [2, 5, 10, 20, 50]
train_scores, test_scores = [], []
for s in splits:
clf = RandomForestRegressor(min_samples_split=s, random_state=42)
clf.fit(X_train, y_train)
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot([str(s) for s in splits], train_scores, marker='o', label='Train Accuracy')
plt.plot([str(s) for s in splits], test_scores, marker='s', label='Test Accuracy')
plt.xlabel('min_samples_split')
plt.ylabel('Accuracy')
plt.title('Effect of min_samples_split')
plt.legend()
plt.grid(True)
plt.show()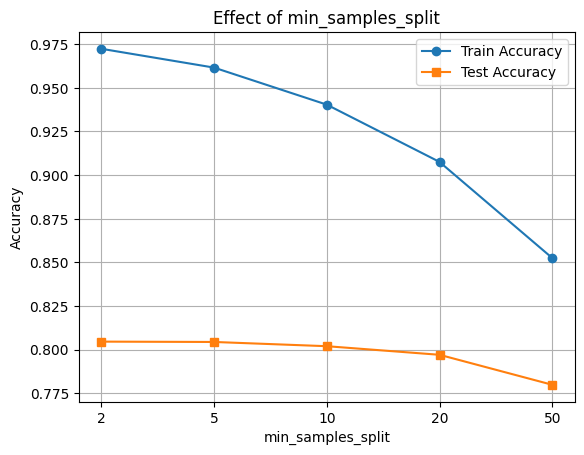
🔍 Feature Importance with SHAP
Now let’s interpret the model using SHAP values to see which features were most influential.
final_clf = RandomForestRegressor(n_estimators=100, max_depth=8, max_features='sqrt', random_state=42)
final_clf.fit(X_train, y_train)
# Accuracy
train_acc = r2_score(y_train, clf.predict(X_train))
test_acc = r2_score(y_test, clf.predict(X_test))
print(f"Train R2: {train_acc:.3f}")
print(f"Test R2: {test_acc:.3f}")Train R2: 0.853
Test R2: 0.780🧠 Feature Importance with SHAP
We’ll use SHAP (SHapley Additive exPlanations) to understand how different features contribute to the model’s predictions.
This helps us: - Identify the most influential features - Understand direction and magnitude of impact
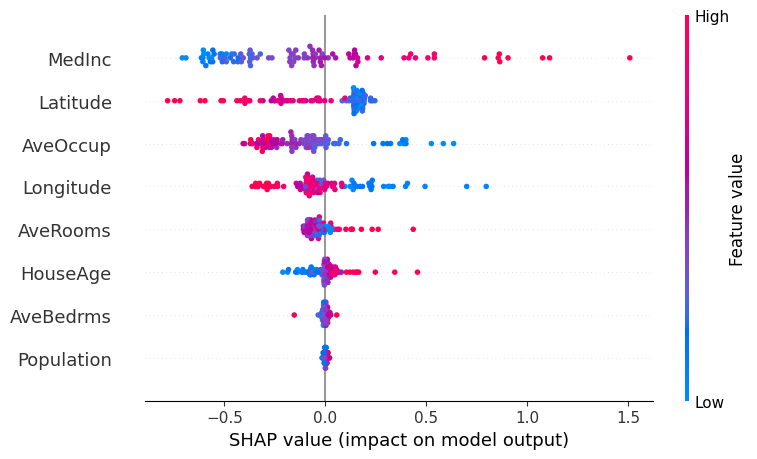
📊 Interpreting the SHAP Summary Plot
The SHAP summary plot visualizes how each feature contributes to the model’s output across all samples. Here’s what each component means:
| Element | Description |
|---|---|
| Y-axis (Feature Names) | Features are sorted by overall importance (top = most important). |
| X-axis (SHAP value) | The impact of that feature on the model’s prediction. |
| Each Dot | A single row/sample in the dataset. |
| Color (Dot Hue) | The feature value for that sample — red = high, blue = low. |
| Direction of SHAP Value | Positive SHAP value pushes the prediction toward the positive class (e.g., “disease” class). |
| Negative SHAP value pushes it toward the negative class (e.g., “no disease”). |
🧠 Example Interpretation:
If the “Age” feature has mostly red dots (high values) with positive SHAP values, it means higher ages are pushing predictions toward the positive class.
import shap
explainer = shap.Explainer(final_clf, X_train)
n_datapoints = 100
shap_values = explainer(X_test[:n_datapoints])
shap.summary_plot(shap_values, X_test[:n_datapoints])