import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from xgboost import XGBRegressor
import shap
from sklearn.metrics import r2_score
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing(as_frame=True)
df = housing.frame
X = housing.data
y = housing.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
XGBoost Regression with Heart Disease Dataset
Gradient Boosting is a powerful ensemble technique that builds models sequentially. Each new model is trained to correct the errors made by the previous models. The idea is to minimize a loss function (like log loss for regression or MSE for regression) by adding weak learners (usually shallow decision trees) in a stage-wise manner.
🔁 Core Idea of Gradient Boosting
At each step, a new model is trained to predict the residuals (errors) of the previous model: \[ \text{Residual}_i = y_i - \hat{y}_i \] Then, this new model is added to the overall prediction: \[ \hat{y}^{(t+1)} = \hat{y}^{(t)} + \eta \cdot h_t(x) \] Where: - $ ^{(t)} $: current prediction - $ h_t(x) $: new weak learner (tree) - $ $: learning rate (controls the step size)
🚀 What is XGBoost?
XGBoost (Extreme Gradient Boosting) is an optimized version of gradient boosting that includes several improvements: - Regularization: Prevents overfitting using $ L1 $ and $ L2 $ penalties. - Parallelization: Faster training via parallel tree construction. - Handling of Missing Values: Smart ways to deal with NaNs automatically. - Tree Pruning: Uses a depth-first approach and pruning with a minimum loss reduction (gamma). - Column Subsampling: Introduces randomness (like Random Forest) via colsample_bytree.
📉 Role of the Learning Rate ($ $)
The learning rate determines how much each tree contributes to the final prediction. It’s one of the most important hyperparameters in XGBoost:
| Learning Rate | Behavior |
|---|---|
| High ($ \() | Faster learning but may overfit. | | Low (\) $) | Slower learning, but often better generalization. Needs more trees. |
A small learning rate with a high number of estimators is generally a safer and more robust approach.
📌 Summary:
Gradient Boosting builds an ensemble of models to correct previous mistakes. XGBoost makes this process faster, more regularized, and scalable. The learning rate is a key tuning knob that balances speed and generalization.
We will focus on three key hyperparameters: - n_estimators: Number of boosting rounds. - max_depth: Maximum depth of a tree. - learning_rate: Step size shrinkage used to prevent overfitting.
We’ll also evaluate model performance and interpret it using SHAP (SHapley Additive exPlanations).
🔧 Hyperparameter Tuning: n_estimators
The n_estimators parameter defines the number of boosting rounds (trees). Increasing it can improve performance but might lead to overfitting.
estimators = [150, 200, 300, 500]
train_scores, test_scores = [], []
for n in estimators:
clf = XGBRegressor(n_estimators=n, eval_metric='logloss')
clf.fit(X_train, y_train)
# y_pred = clf.predict(X_test)
# print('R² Score:', r2_score(y_test, y_pred))
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot(estimators, train_scores, marker='o', label='Train R² Score')
plt.plot(estimators, test_scores, marker='s', label='Test R² Score')
plt.xlabel('n_estimators')
plt.ylabel('R² Score')
plt.title('Effect of n_estimators')
plt.legend()
plt.grid(True)
plt.show()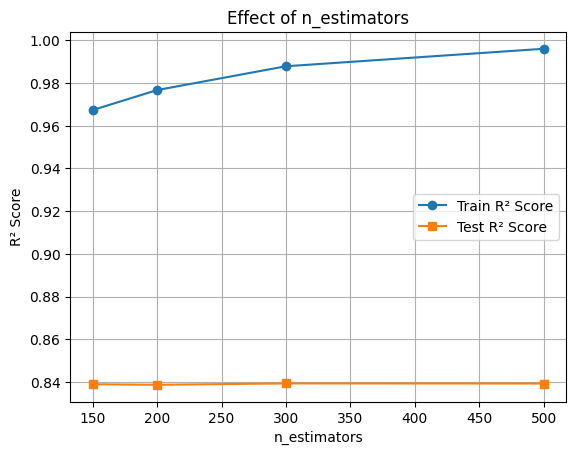
🔧 Hyperparameter Tuning: max_depth
The max_depth parameter controls the complexity of each tree. Deeper trees can learn more complex patterns but may overfit.
depths = [2, 4, 6, 8, 10]
train_scores, test_scores = [], []
for d in depths:
clf = XGBRegressor(max_depth=d, eval_metric='logloss')
clf.fit(X_train, y_train)
# y_pred = clf.predict(X_test)
# print('R² Score:', r2_score(y_test, y_pred))
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot(depths, train_scores, marker='o', label='Train R² Score')
plt.plot(depths, test_scores, marker='s', label='Test R² Score')
plt.xlabel('max_depth')
plt.ylabel('R² Score')
plt.title('Effect of max_depth')
plt.legend()
plt.grid(True)
plt.show()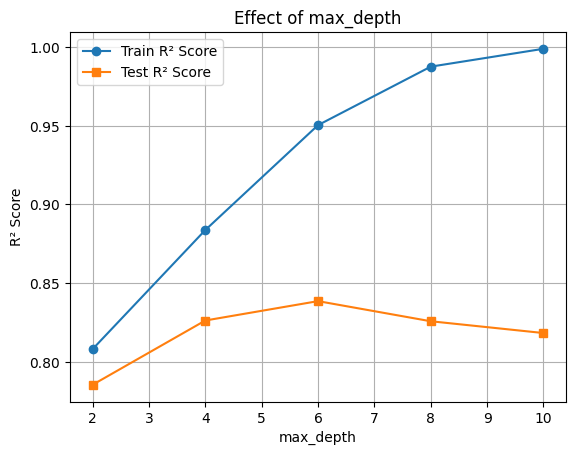
🔧 Hyperparameter Tuning: learning_rate
The learning_rate parameter shrinks the contribution of each tree. Lower values require more trees but improve generalization.
rates = [0.01, 0.05, 0.1, 0.3, 0.5]
train_scores, test_scores = [], []
for rate in rates:
clf = XGBRegressor(learning_rate=rate, eval_metric='logloss')
clf.fit(X_train, y_train)
# y_pred = clf.predict(X_test)
# print('R² Score:', r2_score(y_test, y_pred))
train_scores.append(r2_score(y_train, clf.predict(X_train)))
test_scores.append(r2_score(y_test, clf.predict(X_test)))
plt.plot(rates, train_scores, marker='o', label='Train R² Score')
plt.plot(rates, test_scores, marker='s', label='Test R² Score')
plt.xlabel('learning_rate')
plt.ylabel('R² Score')
plt.title('Effect of learning_rate')
plt.legend()
plt.grid(True)
plt.show()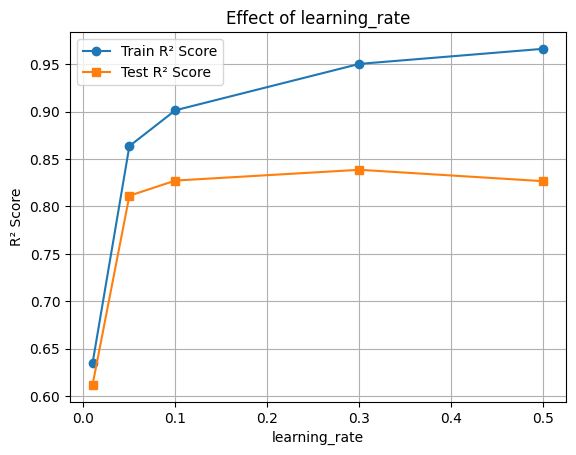
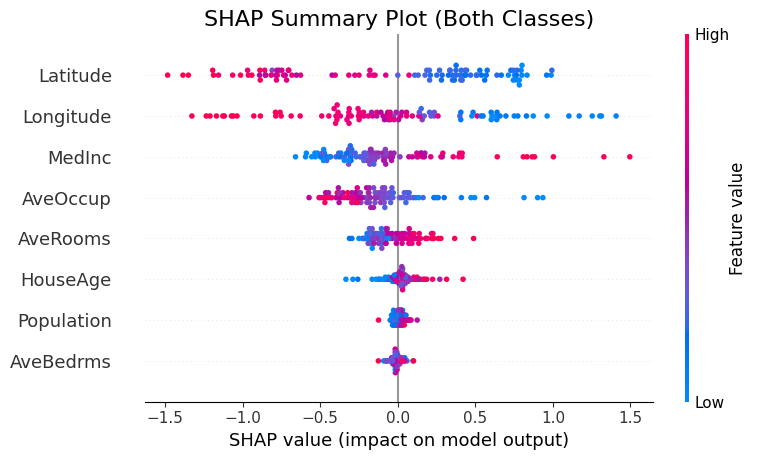
🔍 Feature Importance with SHAP
Now let’s interpret the model using SHAP values to see which features were most influential.
final_clf = XGBRegressor(learning_rate=0.1, max_depth=10,n_estimators=200, eval_metric='logloss')
final_clf.fit(X_train, y_train)
y_pred = final_clf.predict(X_test)
print('R² Score:', r2_score(y_test, y_pred))
# R² Score
train_acc = final_clf.score(X_train, y_train)
test_acc = final_clf.score(X_test, y_test)
print(f"Train R² Score: {train_acc:.3f}")
print(f"Test R² Score: {test_acc:.3f}")R² Score: 0.8315977482997928
Train R² Score: 0.996
Test R² Score: 0.832🧠 Feature Importance with SHAP
We’ll use SHAP (SHapley Additive exPlanations) to understand how different features contribute to the model’s predictions.
This helps us: - Identify the most influential features - Understand direction and magnitude of impact
📊 Interpreting the SHAP Summary Plot
The SHAP summary plot visualizes how each feature contributes to the model’s output across all samples. Here’s what each component means:
| Element | Description |
|---|---|
| Y-axis (Feature Names) | Features are sorted by overall importance (top = most important). |
| X-axis (SHAP value) | The impact of that feature on the model’s prediction. |
| Each Dot | A single row/sample in the dataset. |
| Color (Dot Hue) | The feature value for that sample — red = high, blue = low. |
| Direction of SHAP Value | Positive SHAP value pushes the prediction toward the positive class (e.g., “disease” class). |
| Negative SHAP value pushes it toward the negative class (e.g., “no disease”). |
🧠 Example Interpretation:
If the “Age” feature has mostly red dots (high values) with positive SHAP values, it means higher ages are pushing predictions toward the positive class.
import matplotlib.pyplot as plt
import shap
# Compute SHAP values for both classes
explainer = shap.TreeExplainer(final_clf, X_train)
shap_values = explainer.shap_values(X_test[:100])
# Increase figure size and adjust layout
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test[:100], show=False)
plt.title("SHAP Summary Plot (Both Classes)", fontsize=16)
plt.tight_layout()
plt.show()